Using Prisma with Nextjs at scale

Prisma
Prisma is a type-safe and easy-to-use ORM. It started garnering a lot of interest and developers are flocking to use Prisma 2 in their applications. Prisma offers schema-based client-SDK generation, easy migrations, and most of all, type-safety out of the box. Prisma Studio lets you view and modify your database right from the browser. To top the dev experience, they recently announced "Prisma Cloud", a neat cloud-dev environment.
This article assumes that you have general knowledge about using ORMs, Prisma and Nextjs
Superblog
Superblog is a JAMStack blogging platform. And so, your blogs are blazing fast, auto-scalable, have zero server maintenance.
There are multiple modules in Superblog:
- Marketing website (landing page)
- Dashboard (where clients log in and write their posts)
- Clients' blogs
- Superblog admin panel (to manage customers)
- Misc code bases for maintenance and research
As you can probably notice, managing the data layer for all these applications will be not so easy. All the codebases should be in sync with the data schema all the time. Add typescript types to that!
Single source of truth
What I love about Prisma is that it generates the entire SDK that you need to CRUD the database from a single schema file.

Prisma generates types, functions that are needed to perform your business logic. However, the SDK is generated in the node_modules folder and some may think, it's an anti-pattern. But hey, if it works, it works! Everything is type-safe. And, you can use those types in your front-end. Superblog's dashboard is built entirely with REST API (I do dream of switching to GraphQL, which by the way can be auto-generated using Prisma + Nexus). It is a pleasure to use the same auto-generated types on the front-end and backend!
Lot of time can be saved and code works in a predictable way
Reusing the source schema
Prisma's tooling supports analyzing an existing database to generate the client SDK. This is called introspection.
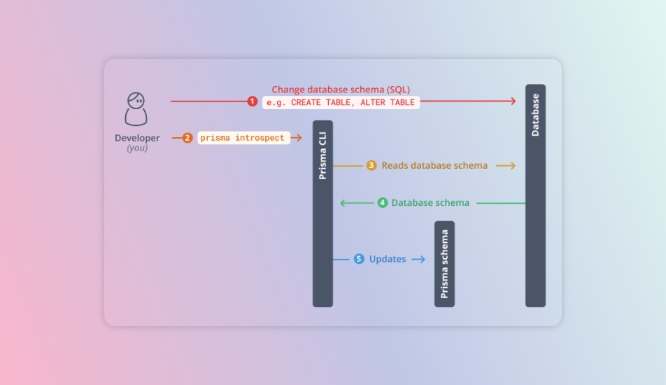
I defined the schema in one codebase and the same is introspected from all other codebases. This way, my data layer is consistent across all my applications - both internal and external. The amount of effort that I have to put in to achieve this is little to minimal.
number of types * functions * REST APIs * number of codebases would've been overwhelming without this approach
Nextjs
Superblog's dashboard is built with Nextjs. There are a number of tutorials on how to use Prisma in Nextjs' API routes. But the thing is, Nextjs is serverless-first and so it converts all the API routes into lambda functions. Generally, this is very good for scalability. We can simply deploy the application to Vercel or Netlify and focus on business logic instead of DevOps. Except it is not that straightforward.
Cold starts
This is not specific to Nextjs but to the concept of Serverless architecture. The functions aka routes aka underlying hardware go to sleep when there is no activity for a certain period of time. When a new request hits the endpoint, the serverless functions i.e in this case Nextjs API route functions are invoked, and Prisma Client is initialized. The total time taken for this depends on the platform where you deploy but mostly everybody is catching up.
To fix this:
- We can keep the functions warm.
- Prisma can be initialized outside of the function (route) handler to keep the DB connection alive. For some time.
However, there's still a delay in starting the function + connecting to DB. I want to give a blazing fast experience throughout the Superblog's workflow. So, this is a major problem for Superblog!
Connection Hell -> Pool
What we achieved with serverless, the infinite auto-scaling will now cause another issue. As the number of requests to our serverless application increases, new instances are spun on-demand. Which means more connections to the database. If you are using any of the managed databases (you should) from AWS, Azure, or Digital Ocean, etc. the number of simultaneous connections will get exhausted pretty quick. This can be solved by:
- Upgrading the database capacity
- Using a connection pooler
- Switching to a serverless-first database
- API-first databases (http(s)-only CRUD)
But we want to use Postgres for Superblog's data. Using a connection pooler is a no-brainer and I think it should be a default for all scenarios anyway. At the time of writing his article, Prisma teased a data proxy to solve this exact problem.
However, I had to find a way to overcome both of these problems for better UX and scalability.
Custom server in Nextjs
Nextjs app can be converted into a pure nodejs app with just a few lines of code. And when I say nodejs app it should obviously be an express server app.
By defining a custom server for superblog's dashboard, I was able to initialize Prisma once only 1 connection call to the database, (however, Prisma maintains a pool that can be controlled). Next, the prisma object is passed on to all the routes of the application via Express' req object. Business logic can be performed in the REST endpoints (routes) with the same Prisma object. Suddenly, our capacity to handle requests shot up drastically!
Phew! We just solved the problem of cold starts and connection hell (connection pooling can still be used).
What about auto-scaling the dashboard?
A spike in traffic can take down our nextjs app (which is nothing but an express node app) because both Vercel and Netlify don't support this approach. One obvious way is to deploy our node app on EC2 and set up load balancer + auto-scaling groups.
I'm not a huge fan of this either. So, I containerized the entire nodejs app and deployed it using caprover. Caprover is basically an open-source Heroku using docker (you can use dokku too). So, with docker-swarm, I'm able to auto-scale the nodejs app. However, there are other easy and cheap solutions like render.com and AWS AppRunner. As a matter of fact, I did deploy Superblog to render but moved to AWS (because of credits). If AWS App runner wants to be taken seriously, they should beat the DX of render. Sorry, I digress.
Conclusion
What goes around, comes around
We have kind of come full circle - taking a serverless-first framework and making it a server-app and then containerizing the whole app to auto-scale (serverless yay!). But it works! Works fantastically. Now, depending on the number of requests, compute (and ram) load, new containers will be spun to maintain the performance of superblog's dashboard.
